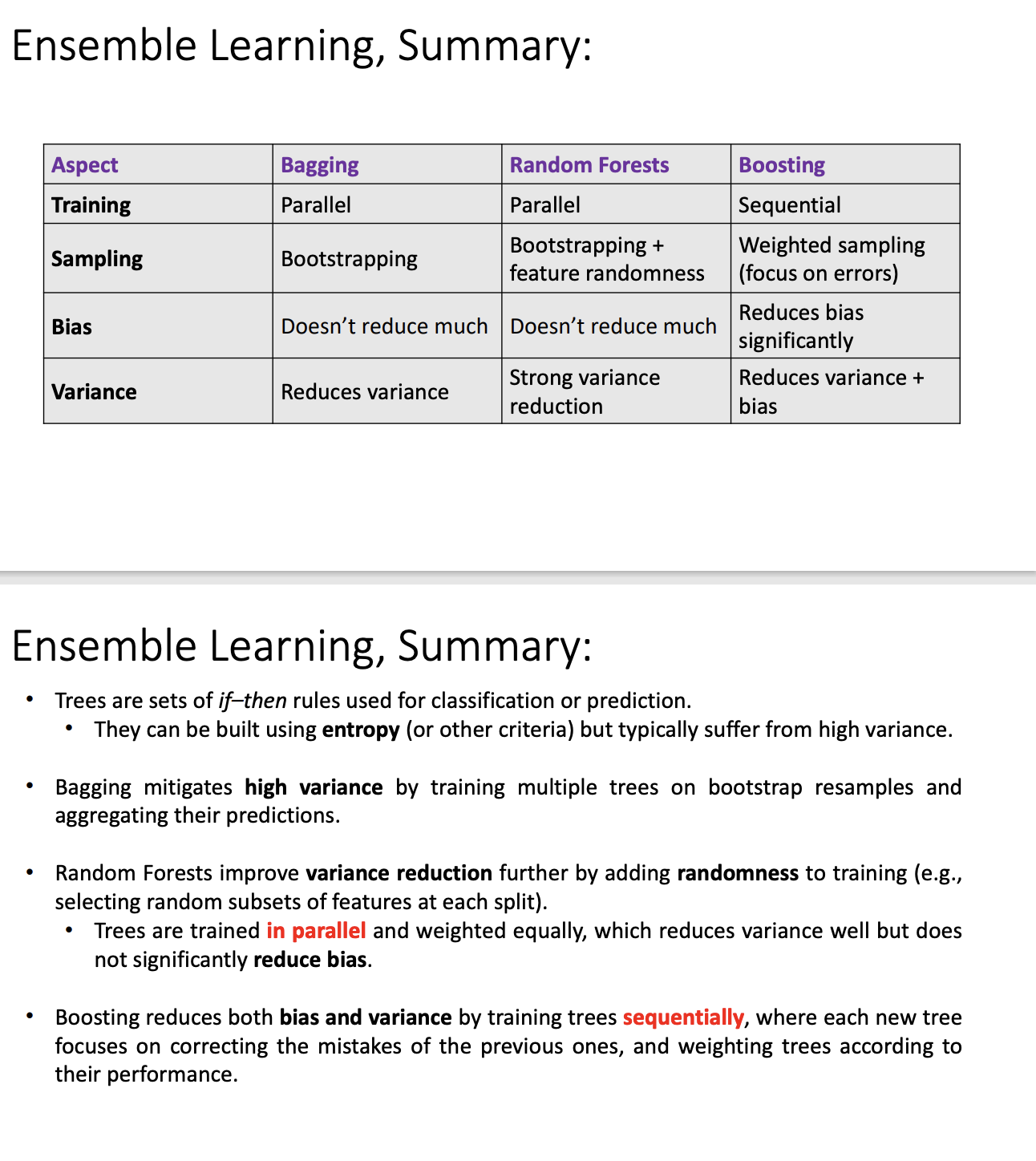
Adaboost 特点🔗 每次迭代选择一个弱分类器,然后根据弱分类器的错误率来调整样本的权重 分类错误的样本权重增大,分类正确的样本权重减小 然后把弱分类器和调整后的样本权重存储起来,最后把弱分类器组合起来,形成一个强分类器。 串行计算,每次迭代都需要重新计算样本权重,计算量大 总结"就是通过迭代对数据权重更新,进而计算出弱分类的器的alpha" alpha的公式来自于计算-最小化指数损失函数(exponential loss) 图示🔗