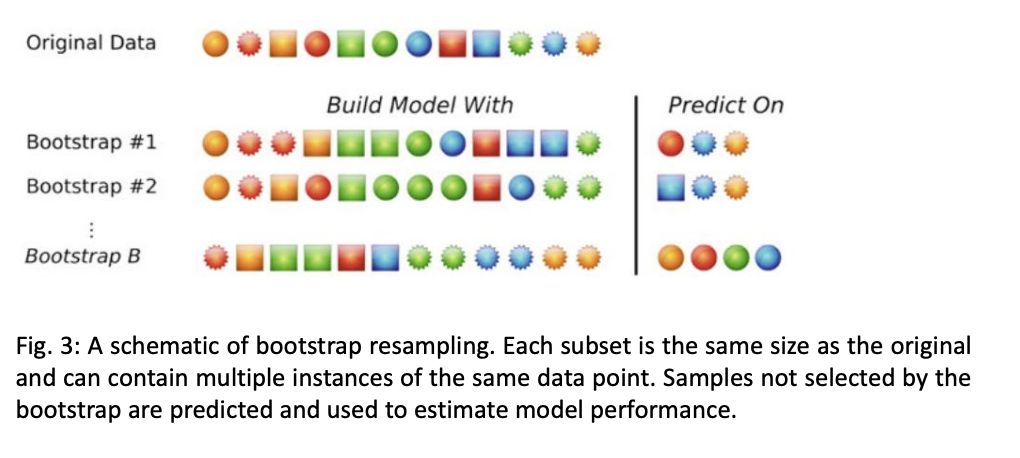
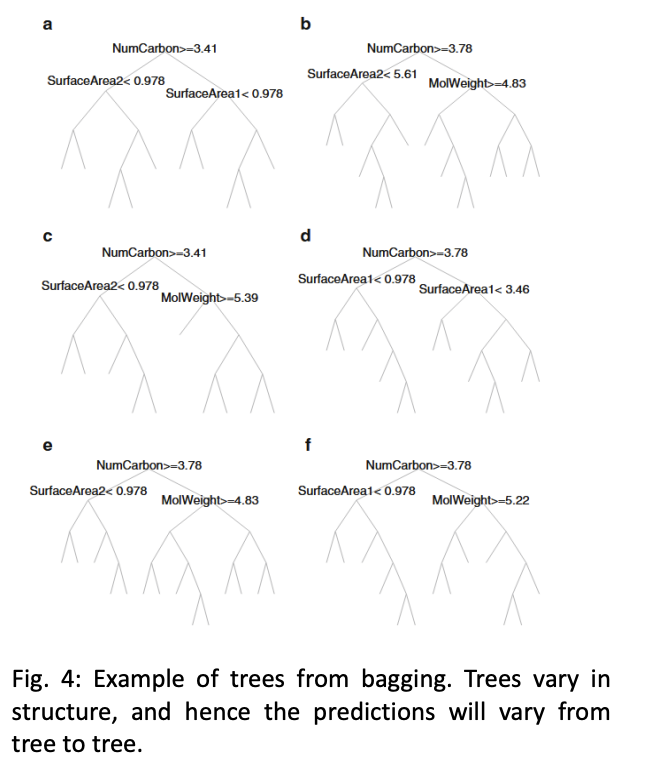
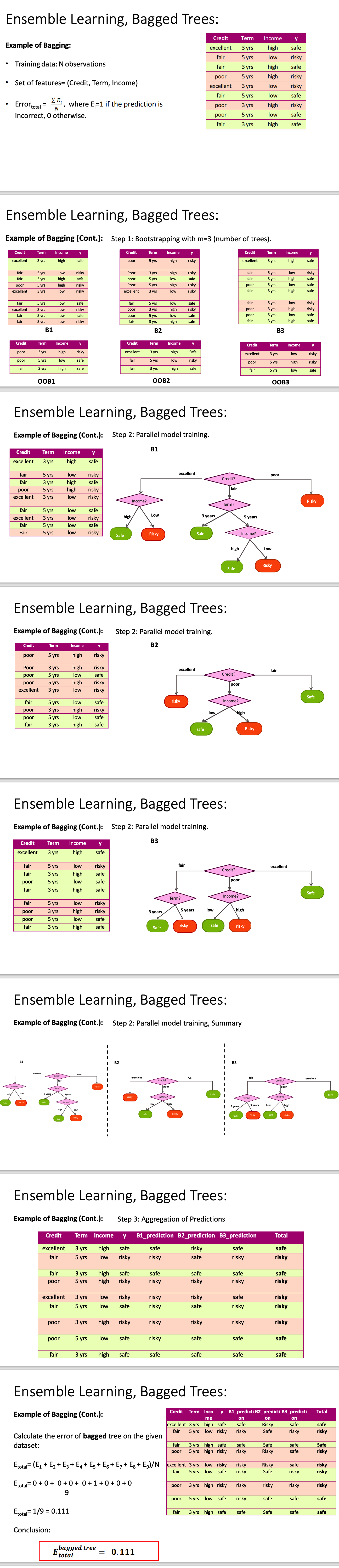
Bagging 特点🔗 通过 bootstrapping (有放回采样)来生成多个训练集 多个训练集大小相同,但样本不一定相同 某些样本可能在多个训练集中出现, 也可能不出现 未出现的样本被称为 out-of-bag 样本 不用从数据集分离测试集; 使用out-of-bag (OOB) 样本来评估模型 每个参与bagging的model产生一个预测, 最终的预测是所有预测的平均值/多数投票 降低了方差 可以并行计算 每个树最终都是独立的,但仍然存在一定的相关性 可以通过增加随机性来降低相关性 图示🔗